具身智能正在经历一场从“拼本体”到“拼数据”的产业转折。
过去两年,行业角逐的焦点,更多是谁能率先造出能跑、能跳、能执行多样化任务的本体。而进入2026年,竞争的焦点正悄然转移——谁能率先拿到百万甚至千万小时级的真实物理数据,谁就掌握了定义下一代具身智能的话语权。
但数据的采集,远非“砸钱”就能解决。规模、质量、生态、标准——每一个环节都卡着行业的脖子。这场数据竞赛,正在成为具身智能产业新的分水岭。
数据缺口:比想象中大
具身智能产业发展,究竟需要多少数据?
星海图CEO高继扬作过一个类比:GPT等大语言模型今天的训练Token数,如果换算到具身基础模型训练领域,大约落在百万小时到千万小时之间。
因此,他的判断是:在百万到千万小时之间的某一数据量级,训练出的具身基础模型将带来突破性改变。
这是一个什么概念呢?
“一个人从0到18岁,醒着的时间和物理世界交互的总时长大概是10万小时。也就是说,人的大脑用了10万小时学会了怎么驾驭自己的身体。100万小时相当于约8.3个人类的学习总时长,1000万小时相当于约83个人。”高继扬表示。

而如果以自动驾驶行业作为参照,光轮智能创始人兼CEO谢晨认为,物理AI的数据需求规模,是自动驾驶的1000倍。
然而,理想与现实之间,鸿沟是巨大的。
据相关统计数据,截至2026年初,全球高质量真实物理交互数据总量也不过50万小时,距离行业公认的千万小时级数据需求量,缺口超95%。
这背后,2026年以前,全行业的数据量基本在几千到几万小时徘徊,最多的也不过十几万小时。直到今年,头部企业才开始迈入百万小时量级。
比如千寻智能,目前已在全国100多个城市布局了30多万个采集点位,专职数采人员超过千人。即便如此,截至今年一季度,千寻智能在真实世界采集的数据规模也才突破10万小时。按照规划,千寻智能今年真实交互数据量将突破100万小时。
星海图也计划今年能完成100万小时真实数据采集,未来三年进一步达成1000万小时。
头部企业尚且如此,大量中小创业者的处境可想而知。
那么,既然行业早有共识,钱投了、人也派了,为什么数据缺口还是填不上?
近日在2026智源大会上,破壳机器人创始人、清华大学交叉信息研究院助理教授许华哲指出,这主要受限于数据采集方式——早期数据基本依赖人工操控真机完成,难点集中在三个方面:一是机器人量产能力不足,无法大批量部署采集设备;二是硬件成本高昂,每台采集机器人的造价都不低;三是设备体积笨重,比如入户采集时需专门运输搬运,流程十分繁琐。
正是因为这些缺点,使得依赖真机遥操作的数据采集路线,从底层逻辑上就难以规模化。
谢晨亦直言,不同于大语言模型拥有互联网作为天然预训练语料,自动驾驶拥有量产车队与司机行为构成的真实数据闭环,具身智能没有任何免费、标准化、可直接使用的预训练集,这是最根本的短板。
另外,自动驾驶的交互主要是车辆与地面动力学的有限维度交互,而具身智能需要复刻人类全场景精细物理操作,涉及海量高自由度、高精度的力与姿态交互,无论研发难度还是数据需求,都远超自动驾驶。
更何况,真机数据的采集远非“采了就能用”那么简单。更大的挑战在于,花了钱、花了时间,采到的数据可能高度同质。
“目前,整个行业普遍存在模态质量差、样本重复度高的问题,极大影响了模型训练效果。”蚂蚁灵波科技CEO朱兴表示。

换言之,采什么样的数据,其实远比采多少数据更为重要。
大量同质数据的积累,非但不能为模型带来新的认知边际,反而可能因存储与训练成本的膨胀,拖慢实际研发节奏。
“比如物流场景、家庭场景,所需收集的数据种类就完全不同,因此,我们希望未来能针对一些垂直可落地的场景,收集更高质量的数据,将单一场景做深做透,这样才能让模型更快实现落地。”星源智创始人兼CEO刘东表示。
而在朱兴看来,未来数据模态也应更加丰富。“人类在物理世界活动,本身就是依赖多种感知模态,因此原生多模态数据能够更好地辅助智能体完成思考与执行。”
流形空间CEO武伟甚至认为,除了真实场景的成功操作数据,真实的失败数据,同样非常宝贵。
这意味着,当前行业面临的并不是单一维度的“数据荒”,而是在数量、质量、模态、场景分布等多个维度同时承压。
数据采集:比想象中难
面对数据困境,业界已经开始积极行动。但“怎么采”的问题,远比想象中复杂。
过去两三年,行业主流方式是人工遥操作真机采集数据,这种模式虽被视为具身智能落地不可或缺的一环,但成本高、效率低、迁移难等先天短板,使其规模化天花板清晰可见。更关键的是,遥操作在视觉、力觉、触觉等多模态数据的同步采集上,也存在明显缺失。
受限于真机遥操的种种瓶颈,仿真合成数据成了行业寻求突破的另一条路径。
相较于前者,仿真合成具备可并发运行、快速搭建场景、低成本试错等多重优势,几乎完美弥补了真机采集的短板。
甚至在谢晨看来,由于具身智能短期内无法实现百万级真机落地,决定物理AI 99.9%的训练数据无法来自本体,仿真将是物理AI唯一的规模化评测路径,也是行业破局的唯一出路。
例如光轮智能的“数据生成-模型训练-能力评测”闭环,使原本需要3-6个月的开发周期,可缩短至2-3周,从而大幅降低企业的综合成本。
不过,仿真合成也存在明显的局限性:与真实场景之间存在不可忽视的sim-to-real gap,比如真实世界中的光照、材质摩擦系数、物体形变、意外扰动等细节,都很难通过仿真完成精确建模。
在此背景下,具身数据采集方式迎来了一场新的范式转移——“以人为中心”的数采方式,成了新主流。

不久前,中国移动与戴盟机器人宣布了一项重磅合作:双方将依托中国移动遍布全国的数十万家线下营业厅,共建一张“外发式”数据采集网络。普通市民经过短期培训,戴上二指夹爪、触觉手套和头戴相机,即可在家居、物流、制造等五大场景中成为数据采集员。
按照规划,该项目满产状态下年产出预计可达100万小时的真实场景数据。
更早一些时候,京东也宣布将发动数十万人参与数据采集,目标一年内积累500万小时人类真实场景视频数据,两年内突破1000万小时,同步实现采集机器人本体数据100万小时。
在朱兴看来,这样的UMI采集方式,尤其是搭配了高精度、易携带的触觉手套,同步补齐视觉与力觉数据后,是当前亟需落地的方向,也是未来搭建高质量数据体系的关键。
许华哲亦表示,他更看好UMI这类新型数据形态,以及穿戴式采集方案。“我们可以在一座城市里招募参与者,每月提供补贴,邀请大家参与采集。哪怕是居家群体、自媒体从业者、全职家长,都可以利用闲暇时间兼职采集,参与者能获得额外收入,我们也能快速拿到高质量的大体量数据,采集效率得到了质的提升。”
但“能采”不等于“能用”。
“以人为中心”的数采方案,虽然可以大幅提升数据采集效率,同样面临“质”的挑战——如果只是让大量人群随意佩戴设备录制日常活动,采集到的数据可能高度同质化,且缺乏精细的动作标注。
这意味着,对数据质量的管控将至关重要。而不同来源数据的局限,也促使行业正在形成一个新的共识:对通过不同方式获取的数据,应分阶段、分层使用。
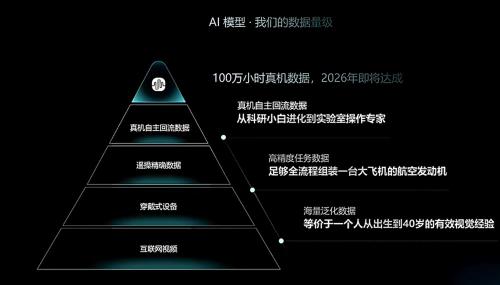
比如在预训练阶段,互联网上大量的人类操作视频虽然缺乏精确的动作标注,但足以让模型初步理解“人类在物理世界中是如何行动的”,建立起基础的世界认知。
“我们在物理世界采集的这些数据,打个形象的比方,就是机器人的引导程序。”千寻智能联合创始人、首席科学家高阳认为,也即是先让模型具备基本的行为直觉,再进入精细打磨。
而进入微调和部署阶段后,由于模型要在具体场景中完成具体的任务,真机数据在这个阶段的价值迅速凸显。
甚至在高阳看来,机器人研发初期,一定要先在物理世界完成海量数据采集——既包括互联网上的人类行为视频,也包括物理世界中的真实场景数据,以此将模型训练到只需几分钟数据微调,就能在任意任务上达到接近95%的成功率,此时模型就可以投入实际场景使用。
后续再通过实际使用迭代形成数据闭环,最终获得超大规模、覆盖真实场景、不存在分布偏移的优质数据源。
从这一点来看,当前行业的数据之争,不仅仅是“采得多”的竞争,更是“采得好”“用得对”的竞争。
数据生态:比想象中急
在数据困局面前,产业链正在达成一个新共识:这不是一场可以靠一己之力赢下的战争。
由于具身智能对数据的需求远超以往,其规模是自动驾驶的上千倍,是大语言模型的上百万倍。这种爆炸式需求,依靠任何一家公司单打独斗都无法满足。
更严峻的是,当前行业正深陷“数据孤岛”的困局。企业各自为战,重复投入大量资源去采集相似的数据,但由于数据存储格式、元数据形态、标注颗粒度存在差异,彼此间的数据流通几乎成为奢望。这种封闭模式造成了巨大的资源浪费,也严重拖慢了整个行业的发展速度。
正因为如此,打破孤岛、共建生态,正在成为头部企业的共同选择。
比如星海图,就于上半年联合亦庄机器人公司和亦庄国投共同发起成立了“亦数智能”,目标围绕物理世界百万到千万小时的数据累积展开深入工作。目前,首批15家合作伙伴已签约加入。
光轮智能选择了另一条路:横向整合产业链。过去两个月,光轮智能先后与PICO、阿里云、舞肌科技、宝通科技、生数科技等多家企业达成生态合作,覆盖数据采集硬件、云端算力平台、场景落地、行业标准等多个环节。其意图很明确——成为物理AI基础设施层那个“绕不开的角色”,让自身的数据闭环能力嵌入产业链的每一个节点。

它石智航则发起了“具身数据星火计划”,以Human-centric数据范式为核心,目标初期汇聚超过1000万小时的标准化优质数据,并通过建立安全合规、高效标准的数据采集与共享机制,推动实现1亿小时级别的数据共享。目前,库帕思、国地上海、联想、联宝、建发等已作为合作方加入。
三条路径,殊途同归——都在试图回答同一个问题:如何让数据从“私有资产”变成“公共基础设施”?
与此同时,北京、无锡等地也在纷纷抢跑具身智能数据赛道,试图依托各自的城市资源,助力行业破解数据瓶颈。这意味着,数据已不再仅仅是企业层面的竞争要素,更已上升为城市乃至国家层面的战略资源。
这种产业链上下游的协同发力,在星海图CEO高继扬看来,将为中国具身智能产业带来显著的优势:“过去行业一直关注中国在硬件、零部件供应链上的优势。但从今年开始,我们的数据供应链优势也会凸显出来。数据工程链优势叠加上整机供应链优势,将在未来2-3年让中国具身基础模型能力超过美国。”
值得关注的是,产业链密集动作的同时,行业标准也在同步推进。
5月初,国家标准化管理委员会正式下达《高质量数据集具身智能面向训练基地的数据采集与模型训练规范》国家标准计划,旨在聚焦“高质量数据集建设”这一核心目标,构建全流程、可落地的规范体系,预计2027年正式发布实施。
该标准的出台,预示着具身数据采集从“手工作坊”走向“工业流水线”,即将有了统一规则。
然而,生态的集结,并不意味着所有人机会均等。恰恰相反,产业内部的分化正在加速。
韩峰涛预判:“今年行业最明显的变化将是:手握海量数据、完成大规模预训练的企业,模型实力会拉开明显差距。而学术机构受数据储备限制,模型表现会相对弱势。”
许华哲更为直接:没有拿到头部资金和数据资源的企业,将失去上桌的机会。
由此可见,除了资金,数据也正在成为决定一家企业能否留在风口上的关键标尺。
结语
伴随着具身智能快速发展,行业正在回归一个朴素的逻辑:谁能用更低成本更高效地获取高质量数据,谁就有望更好地定义下一代具身智能的形态。
毕竟,本体的竞争,拼的是供应链、是量产能力、是工程化水平——这些靠钱和资源可以快速追赶。但数据的竞争,拼的是生态、是标准、是持续进化的闭环——这些,无法速成。
这不是一场短跑,而是一场关于耐心的长跑。
















 扫一扫关注微信
扫一扫关注微信
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}